
You're probably dealing with this already. Your team has one AI workflow for internal ops, another for customer support, and maybe a growing set of client-facing agents that touch Gmail, Slack, HubSpot, Salesforce, or Zendesk. Everything works, until someone asks a hard question: what keeps one workload from seeing another workload's data?
That question gets sharper as you scale. A founder can live with a shared environment for a while. A CTO managing client accounts, regulated data, or multiple AI agents usually can't. One bad permission, one weak boundary, or one compromised service account can turn a contained mistake into a cross-tenant incident.
That's why data isolation matters. Not as a buzzword, but as an architectural decision about where boundaries exist, how strong they are, and what happens when something goes wrong.
Table of Contents
- What Is Data Isolation Really?
- The Two Worlds of Data Isolation Security vs Transactional
- Key Techniques for Achieving Data Isolation
- Practical Implementation Patterns and Trade-offs
- How Donely Delivers Enterprise-Grade Isolation
- FAQ Data Isolation Clarified
What Is Data Isolation Really?
Data isolation means keeping data separated by design so one workload, tenant, client, or environment can't freely access another's data. In security practice, that separation is usually created through a combination of physical barriers, network boundaries, virtualization, and strict access controls, which reduces unauthorized access and limits lateral movement if something gets compromised, as explained in CrashPlan's definition of data isolation.
A simple way to think about it
If you run an agency with AI agents for multiple clients, isolation is the difference between a hotel and a dormitory.
In a dormitory, everyone shares the same space. Privacy depends on people behaving properly. In a hotel, each guest gets a separate room with its own lock, and staff controls who can enter. The building is shared, but access is segmented.
That's how most modern platforms work. They don't always give every customer separate hardware, but they create clear boundaries inside shared infrastructure so Client A's workflows, memory, files, logs, and permissions stay separate from Client B's.
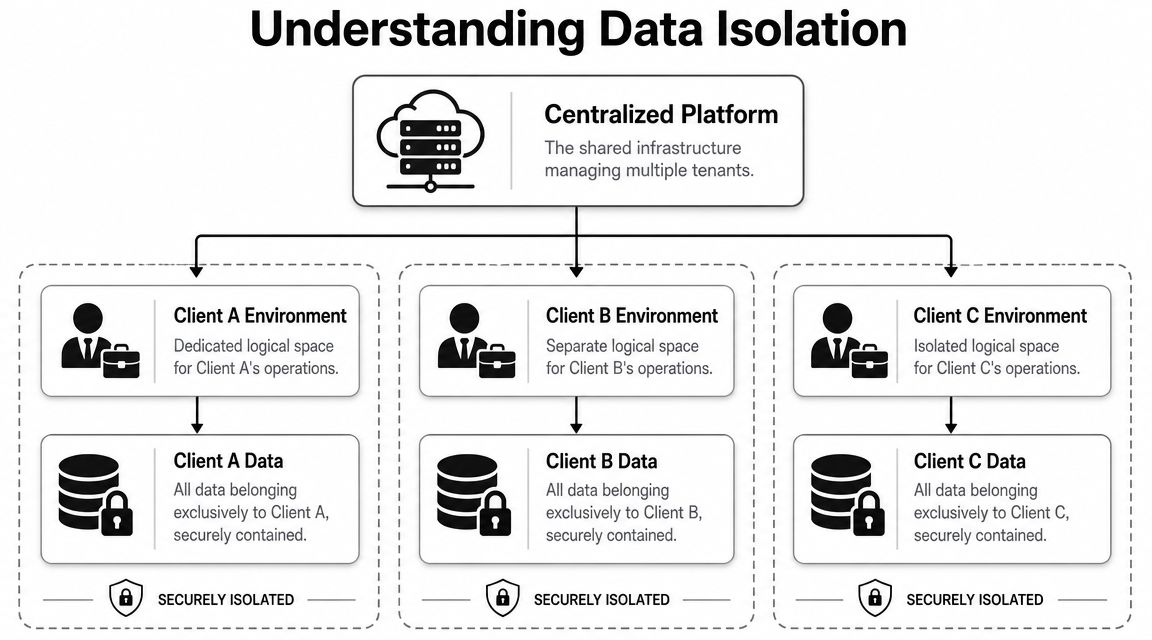
A strong architecture doesn't rely on one control. It layers them. You might have separate containers, scoped credentials, network segmentation, tenant-aware storage rules, and role-based permissions all working together.
Why the boundary matters
The main reason to isolate data is simple. You want failures to stay local.
If an API key leaks, a support admin is over-permissioned, or an agent misbehaves, isolation shrinks the blast radius. The issue can still be serious, but it doesn't automatically become a platform-wide exposure.
Practical rule: Isolation isn't about pretending breaches won't happen. It's about making sure one breach doesn't become every breach.
This matters for compliance, customer trust, and recovery. It also matters for AI systems because agents often connect to many tools at once and can move fast inside the permissions they're given. Without boundaries, convenience becomes risk.
For teams that want a concise statement of this philosophy in product terms, Donely's privacy manifesto describes isolated customer environments as a core principle. That's the right mental model for evaluating any AI platform. Don't ask only whether it supports multiple agents. Ask whether each agent runs inside a boundary you can govern.
The Two Worlds of Data Isolation Security vs Transactional
A lot of confusion starts with one phrase doing two jobs.
When people ask what is data isolation, they often mean security separation between tenants or workloads. Database engineers may hear the same phrase and think about ACID transaction behavior. Both are valid. They are not the same thing.
Security isolation solves access problems
Security isolation is about who or what can access which data.
If your company runs separate AI agents for sales, finance, customer support, and external clients, security isolation answers questions like these:
- Tenant boundaries: Can one client's agent ever query another client's records?
- Environment separation: Can staging data leak into production workflows?
- Access scope: Can a support user see only the instance they manage?
- Containment: If one service is compromised, can an attacker move sideways?
Use the campus analogy. Security isolation is like putting different departments in separate buildings with controlled entry. They may share utilities and a campus network, but they don't share offices, filing cabinets, or door keys.
This is also why application teams should audit low-code and AI-heavy builds with the same discipline they apply to traditional software. A practical reference is Tekk.coach's Vibe coding security audit guide, which helps teams look for hidden trust assumptions and weak boundaries before they become incidents.
Transactional isolation solves concurrency problems
Database isolation is different. It's about how transactions behave when multiple operations happen at the same time.
According to Adivi's explanation of isolation in database systems, isolation means one transaction's intermediate writes stay invisible to others until commit, which prevents issues like dirty reads. Stronger isolation improves integrity, but it usually reduces concurrency. Serializable is the strictest level.
Think of this as library rules, not campus security.
Multiple people can use the same library at once, but the rules determine whether one reader sees another person's half-finished notes, whether two people can change the same record safely, and whether the final state remains consistent.
A tenant can have excellent security isolation and still suffer from poor transaction handling inside its own database workload.
That's the key distinction many teams miss. Separate buildings don't guarantee good library behavior. Likewise, separate tenant boundaries don't automatically make concurrent writes safe.
Key Techniques for Achieving Data Isolation
Architects usually implement isolation with a stack of controls, not one silver bullet. The right mix depends on risk, compliance pressure, and how much operational complexity your team can absorb.
Early in the design discussion, it also helps to anchor isolation inside a wider trust model. CTO Input's guide to zero trust strategies is useful here because zero trust and data isolation reinforce each other. One defines how access is continuously constrained. The other defines where hard boundaries exist.
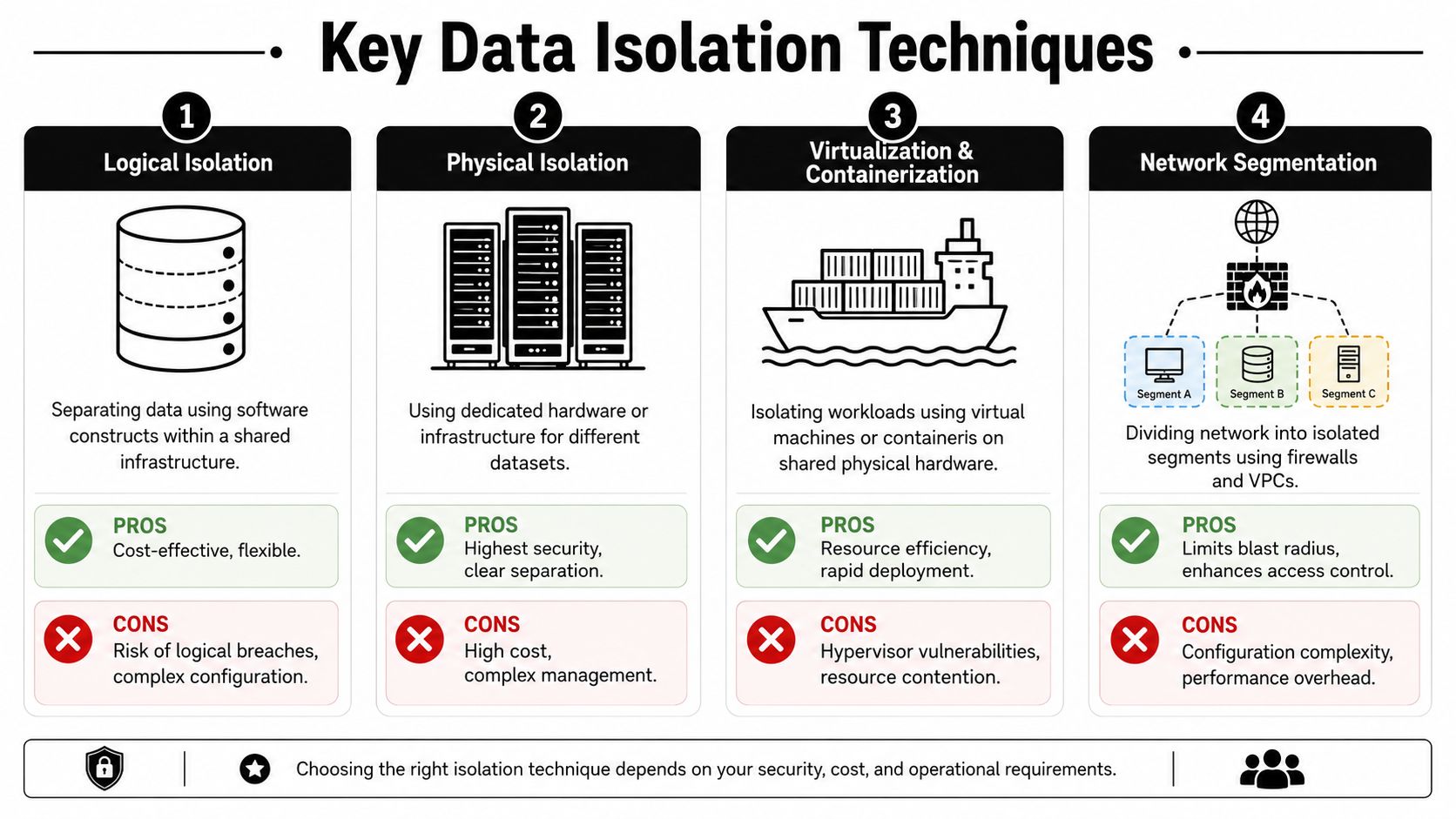
The main isolation patterns
Physical isolation uses dedicated servers or storage for a specific workload or tenant. This gives the clearest separation and is often chosen when data sensitivity is high or when the organization wants the strongest possible boundary.
Network isolation separates traffic paths. Teams use segmented networks, VPC boundaries, firewalls, and tightly scoped routing so services can talk only where explicitly allowed. This is one of the most effective ways to limit lateral movement.
Virtualization and container isolation place workloads into separate virtual machines or containers on shared hardware. This is common in cloud systems because it gives meaningful separation without requiring dedicated infrastructure for every customer.
Logical isolation relies on software controls such as tenant-aware application rules, scoped identities, and access controls. It's flexible and cost-efficient, but it depends heavily on getting the implementation right.
Here's the embedded walkthrough for teams that want a visual overview before comparing models in more detail:
Data Isolation Techniques Compared
| Technique | Mechanism | Security Level | Best For |
|---|---|---|---|
| Physical isolation | Dedicated hardware or storage per workload | Highest boundary strength | Highly sensitive or tightly regulated workloads |
| Network isolation | Segmented network paths and restricted connectivity | Strong when paired with strict policy | Services that must communicate selectively |
| Virtualization and containerization | Separate runtime environments on shared infrastructure | Strong practical separation | Cloud-native platforms and AI workloads |
| Logical isolation | Tenant-aware rules, scoped access, software controls | Depends on implementation quality | Cost-sensitive multi-tenant systems |
| Encryption-based isolation | Customer-specific keys and encrypted stored data | Strong for stored data, but not a full boundary by itself | Data-at-rest protection and tenant-specific cryptographic control |
Where encryption fits
Encryption helps, but it doesn't replace broader isolation.
Qualtrics describes one encryption-based model where a customer-specific Master Key in Amazon KMS is used alongside AES-256-bit encryption for survey data at rest, while also noting important limits: encryption for responses in progress doesn't apply until completion or closure, and the encryption is not retroactive. You can review that implementation detail in Qualtrics' data isolation documentation.
That's a useful reminder. Encryption protects stored data very well in many cases, but it doesn't answer every question about active sessions, in-use data, runtime permissions, or cross-service access.
Encryption is one layer. Isolation is the larger design pattern.
Practical Implementation Patterns and Trade-offs
Every CTO eventually asks the same question. How much isolation is enough?
That's the right question because stronger isolation usually improves containment, but it can also create management overhead, duplication, and coordination complexity. Wasabi's overview of data isolation trade-offs makes this point clearly, especially for organizations running multiple workloads, tenants, or AI agents that need separate permissions and data boundaries.
The architecture spectrum
At one end, you have a fully shared model. One platform, one broad environment, many tenants separated mostly by application logic. This is efficient, simple to operate, and often good enough for low-risk use cases. It's also where implementation mistakes hurt the most.
In the middle, you get logically isolated or multi-instance models. These create stronger boundaries by separating environments, identities, permissions, and often runtime contexts, while still preserving shared control planes for monitoring, billing, or deployment.
At the far end, you have single-tenant or physically isolated deployments. These provide the strongest separation, but they increase provisioning effort, operational overhead, and platform sprawl.
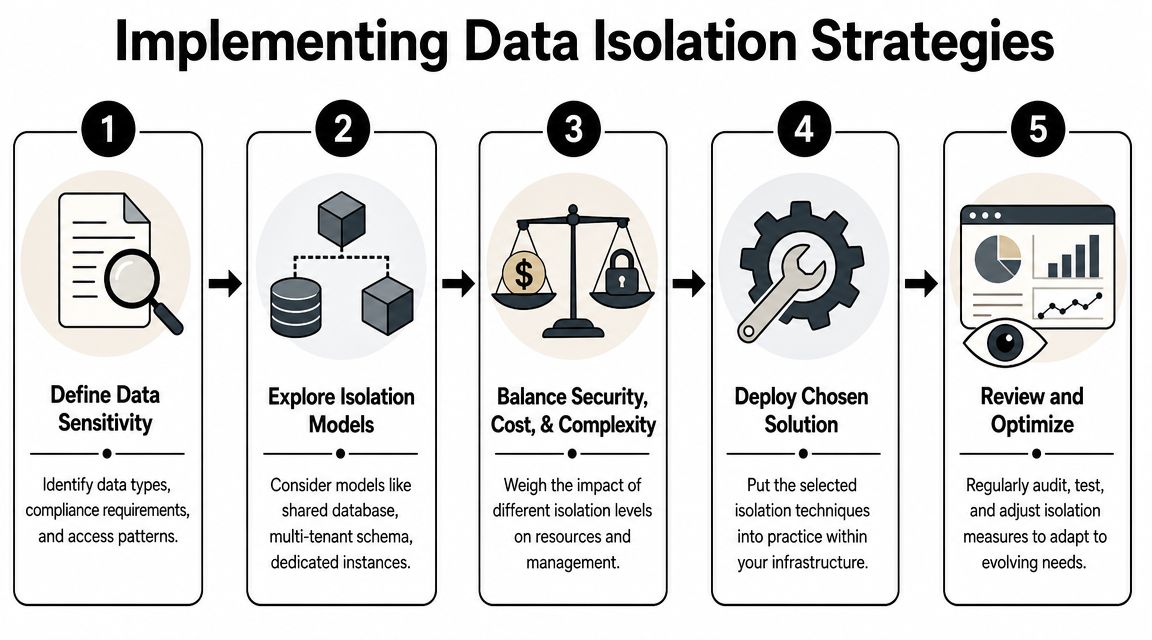
A practical selection framework usually starts with these questions:
- What's the sensitivity of the data. Internal notes, customer records, regulated health data, and financial workflows don't carry the same risk.
- Who needs access. A single founder, an internal team, external clients, and outsourced operators each change the trust boundary.
- What happens if one environment fails. Some incidents are annoying. Others trigger contractual, legal, or reputational fallout.
- How many isolated units will you run. Tenants, departments, and AI agents all add operational surface area.
- Can your team manage the extra overhead. Stronger boundaries only help if your team can provision, audit, monitor, and support them reliably.
Why multi-instance often lands in the middle
For modern AI platforms, multi-instance architecture is often the balanced answer.
It avoids the weakness of “everything in one shared bucket,” but it also avoids forcing every workload onto fully separate infrastructure from day one. Each business unit, client, or use case gets its own environment and access model, while central teams retain enough control to operate the platform sanely.
The best isolation model is rarely the strongest one available. It's the strongest one your team can run consistently without creating chaos.
That's especially true for AI operations. Agents tend to accumulate connectors, permissions, prompts, logs, and knowledge stores. Over time, a shared design becomes hard to reason about. A multi-instance approach keeps the architecture legible. You can answer basic governance questions quickly: Which users have access? Which integrations are connected? Which logs belong to which client? Which data stays in which boundary?
How Donely Delivers Enterprise-Grade Isolation
A lot of platforms talk about isolation in abstract terms. The useful question is whether the product architecture maps cleanly to the control patterns security teams expect.

What the architecture actually does
Donely is relevant here because it uses a multi-instance architecture rather than forcing personal, business, and client workloads into one flat shared space. According to the product information provided, users can run separate instances for different workloads without creating separate accounts or performing migrations.
That maps well to the middle-ground model discussed earlier.
Each instance creates a practical boundary for:
- Scoped data access: an AI agent only sees the data and integrations connected to its instance
- Per-instance RBAC: teams can grant access with more precision instead of exposing a broad shared workspace
- Isolated containers: runtime separation helps keep one workload from freely interacting with another
- Unified audit logs: governance teams still get centralized visibility across isolated environments
For readers evaluating deployment details, Donely's OpenClaw hosting page is the product-level reference point for how those managed environments are positioned.
Why this matters for AI operations
AI systems create a messy mix of permissions and context. An agent might read Slack, send email through Gmail, update HubSpot, create Jira tickets, and write notes into Notion. The hard part isn't spinning the agent up. The hard part is proving that one agent's scope doesn't unintentionally expand into another team's or another client's scope.
Multi-instance architecture helps because it turns “scope” into an operational boundary, not just an application variable.
That matters for agencies handling multiple clients. It matters for internal teams separating HR from sales or support from finance. It matters for enterprises that need auditability and role separation without running a separate platform stack for every use case.
If your AI platform can't express your org chart, client list, and access model as real technical boundaries, you don't have isolation. You have hope.
The value here isn't marketing language. It's that the control surfaces line up with real governance tasks: assign roles by instance, review logs by instance, attach integrations by instance, and contain incidents by instance.
FAQ Data Isolation Clarified
Does isolated data make database transactions safe
No. These are separate concerns.
Security isolation prevents one tenant, environment, or workload from accessing another tenant's data. Transaction isolation controls how concurrent database operations interact. Data Dynamics highlights this distinction directly in its glossary entry on data isolation, including the important clarification that isolated data does not automatically mean your database transactions are safe.
If your platform has strong tenant boundaries but weak database transaction handling, you can still have race conditions, conflicting updates, or inconsistent reads inside a single tenant environment.
When is strong isolation worth it
Strong isolation is worth it when the cost of crossover is high.
That usually includes client-managed environments, regulated workloads, teams with sharply different permissions, and AI systems that connect to sensitive business tools. It's also worth it when support, compliance, or legal teams need clear answers about who accessed what and where the boundary sits.
If the workload is low-risk and tightly controlled by a small internal team, a simpler model may be enough. The mistake is choosing a weak model because it's convenient, then trying to bolt stronger controls onto it after customers or auditors ask harder questions.
How do backups fit into isolation
Backups are part of the isolation story because recovery depends on preserving a clean copy outside the blast radius of the active environment.
Cohesity's data isolation overview describes how modern implementations often use virtual air gaps, transient connections, and layered controls instead of relying only on permanent offline storage. That's important in cloud environments where teams still need recoverable data to be operationally available.
A practical pattern is an immutable or air-gapped backup approach where connections are temporary rather than persistent, and stored snapshots can't be changed or deleted until their expiration period ends.
Is encryption alone enough
Usually not.
Encryption protects stored data well, especially when teams use customer-specific keys and strong controls around key access. But encryption doesn't automatically solve runtime access, permission scoping, network movement, or workload separation.
If a user or service is legitimately allowed into the environment, encryption at rest doesn't stop that principal from misusing its granted access. Isolation needs identity boundaries, runtime boundaries, and network boundaries too.
What should teams review before choosing a model
Start with a short checklist:
- Data sensitivity: What kinds of records will the system process?
- Tenant model: Are you separating internal teams, external customers, or both?
- Access pattern: Which humans, agents, and integrations need to touch the data?
- Recovery plan: How will you restore data without reintroducing compromised state?
- Operational burden: Can your team support the chosen model every day?
Deletion requirements belong on that checklist too. If one client or business unit needs its data removed, the architecture should make that process bounded and auditable. Donely's data deletion information is a useful example of the kind of operational policy teams should look for when assessing a vendor.
The practical takeaway is simple. When someone asks what is data isolation, the right answer isn't just “separating data.” It's separating data with enforceable boundaries that match your risk, your operations, and your recovery plan.
If you're building or scaling AI agents and need clean boundaries between personal, business, and client workloads, Donely is one way to operationalize that with separate instances, scoped access, and centralized oversight from one dashboard.